We give the executable for Linux Ubuntu+code-examples. Sources and Makefiles are also avilable by email to yosi@cs.haifa.ac.il. Since this is an extension of Michael E. Wolf's Tiny system that was availale on the WEB few years ago it is unclear what are the legal permissions available. The source code contains some copyrights restrictions but they all allow using the software.
The HTINY system (Haifa's Tiny) is an extension of Wolf's Auto parallelizing system. The main goal was to transform it to a full source-level HLS compiler that targets both regular CPUs and synthesized circuits. By a source-level compiler we mean a compiler that does not starts by applying code-generation and whose intermediate representation is the abstract-syntax-tree (AST) rather than RTL instructions. We belive that source-level compilation is the key technology to obtain better compilers that can be used to explore different tradeoffs involved with code/circuit generation. The current system contains the following parts added to the original Tiny:
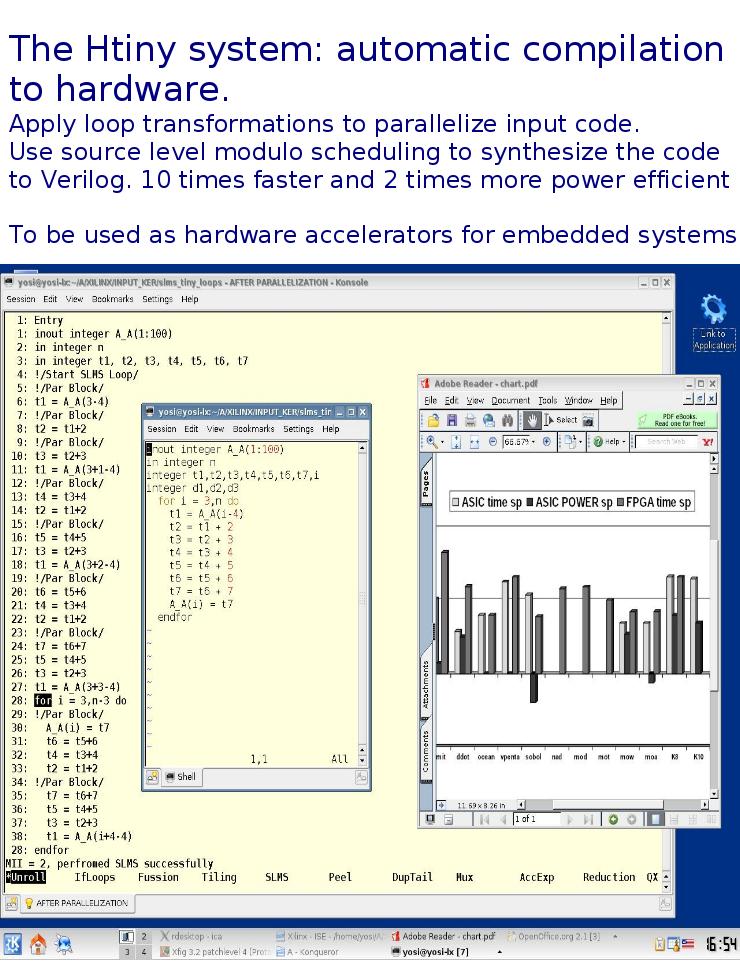
- A set of loop transformations that can be interactively applied to optimize nested loops. These transformations include: uni-modular transformation, loop interchange, loop tiling, loop skewing, loop fusion, loop peeling, loop distribution, and loop flattening. Several other transformations are available to handle conditional statements including: if-conversion (predication), tail-duplication, lifting if-statements by loop splitting, special unroll and jam of if-statements and some form of speculative simplification of if-then-else statements. There are also few transformations that are related to induction variables (IVR), including: IVR substitution and accumulator expansion. This part is not automated and the user must learn by experience which combinations of loop transformations are useful for a given nested loop. An advanced version of loop-unrolling can be used as well. This version expands array expressions in the unrolled iterations.
-
As a separate part the Htiny system has a special synthesis module that synthesize compound loops. In this, we consider a special optimization problem involved with compiling compound loops (combining nested and consecutive sub-loops) with array references to Verilog. Each sub-loop of the compound loop may require a different optimized hardware configuration (OHC) for optimized execution times. For example, one loop requires at least two memory ports and one multiplier for an optimized execution time while another loop may require only one memory port but two multipliers, yet one OHC should be selected for both loops. The goal is to compute a minimal OHC which, based on the different execution frequencies of the sub-loops, is a good compromise between all the conflicting requirements of each sub-loop. Though synthesis of nested loops has been implemented in quite a few systems this aspect has not been considered so far. We avoid the use of Integer Linear Programming (ILP) techniques and instead use a fast space exploration technique that is combined with an efficient variant of list scheduling.
Another novel aspect of the proposed system is the observation that the real latencies of the hardware units should be considered as variables of the OHC rather than fixed real values as is usually done in high-level synthesis systems. Experimental results show a significant improvement in the OHC without a significant increase in the execution time due to the use of this search procedure. configuration
{kind=link}
Modulo scheduling (MS) is a technique in which a loop is parallelized by overlapping different parts of successive iterations. This ability to extract parallelism makes MS an attractive synthesis technique for loop acceleration and is applied as a separate module of HTINY. Current MS scheduling techniques sacrifice execution times in order to meet resource and delay constraints. Let ``ideal'' execution times be the ones that could have been obtained by MS had we ignored resource and delay constraints. Here we pose the opposite problem, which is more suitable for HLS, namely, how to reduce resource constraints without sacrificing the ideal execution time. We focus on reducing the number of memory ports used by the MS synthesis, which we believe is a crucial resource for HLS. In addition to reducing the number of memory ports we consider the need to develop MS techniques that are fast enough to allow interactive synthesis times and repeated applications of the MS to explore different possibilities of synthesizing the circuits. We have formalized the problem of reducing the number of parallel memory references in every row of the kernel by a novel combinatorial setting. The proposed technique is based on inserting dummy operations in the kernel and by doing so, it performs modulo-shift operations such that the maximal number of parallel memory references in a row is reduced. Experimental results suggest improved execution times for the synthesized circuit even compare to commercial tools. The synthesis takes only a few seconds even for large size loops.
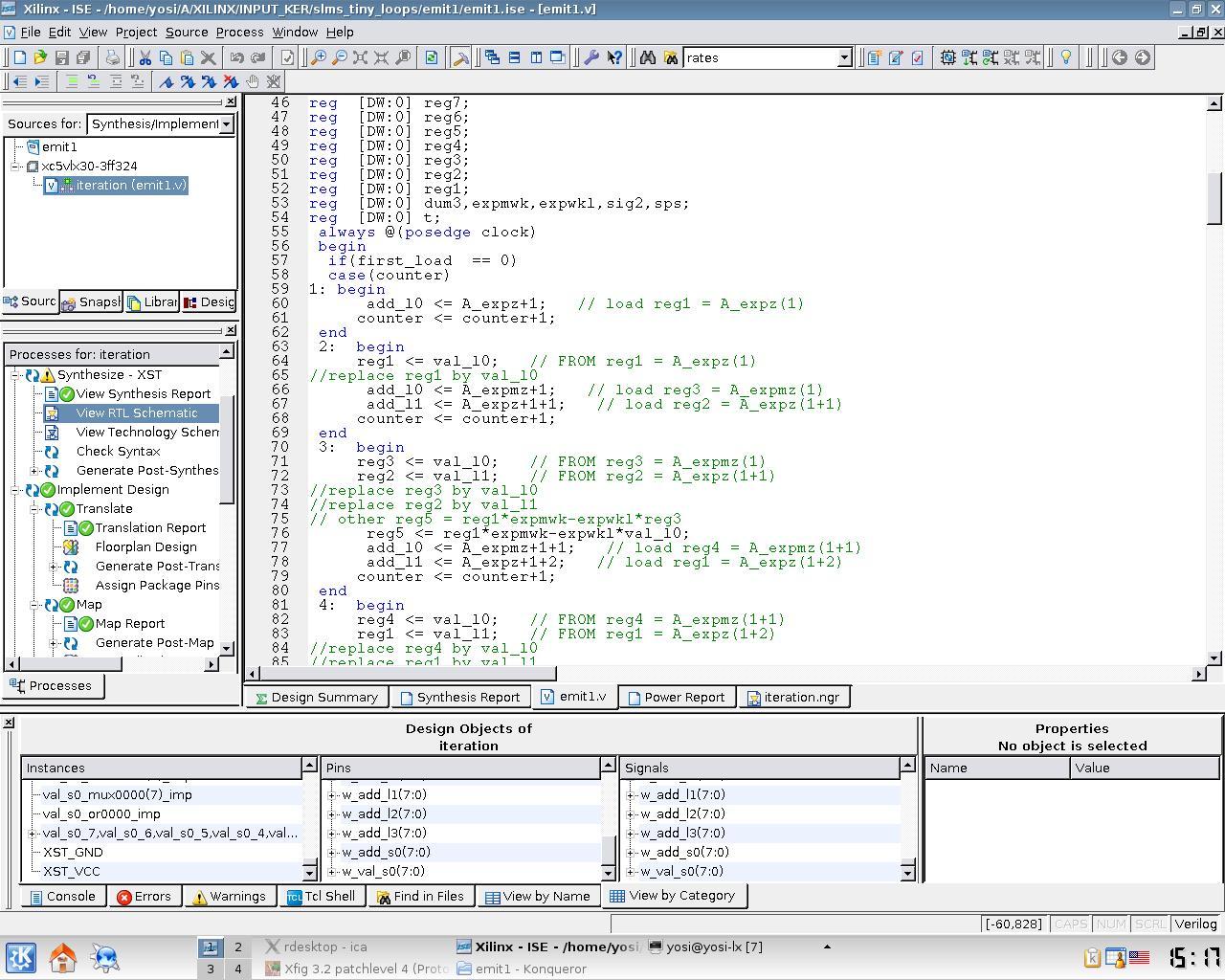
HTINY accepts inputs in a Fortran style but can be applied to C-code using a conversion tool. Pointers are not supported and function calls are supported by the loop transformations part but not by the two synthesis parts.. Htiny contains a back-end to x86 machine code.
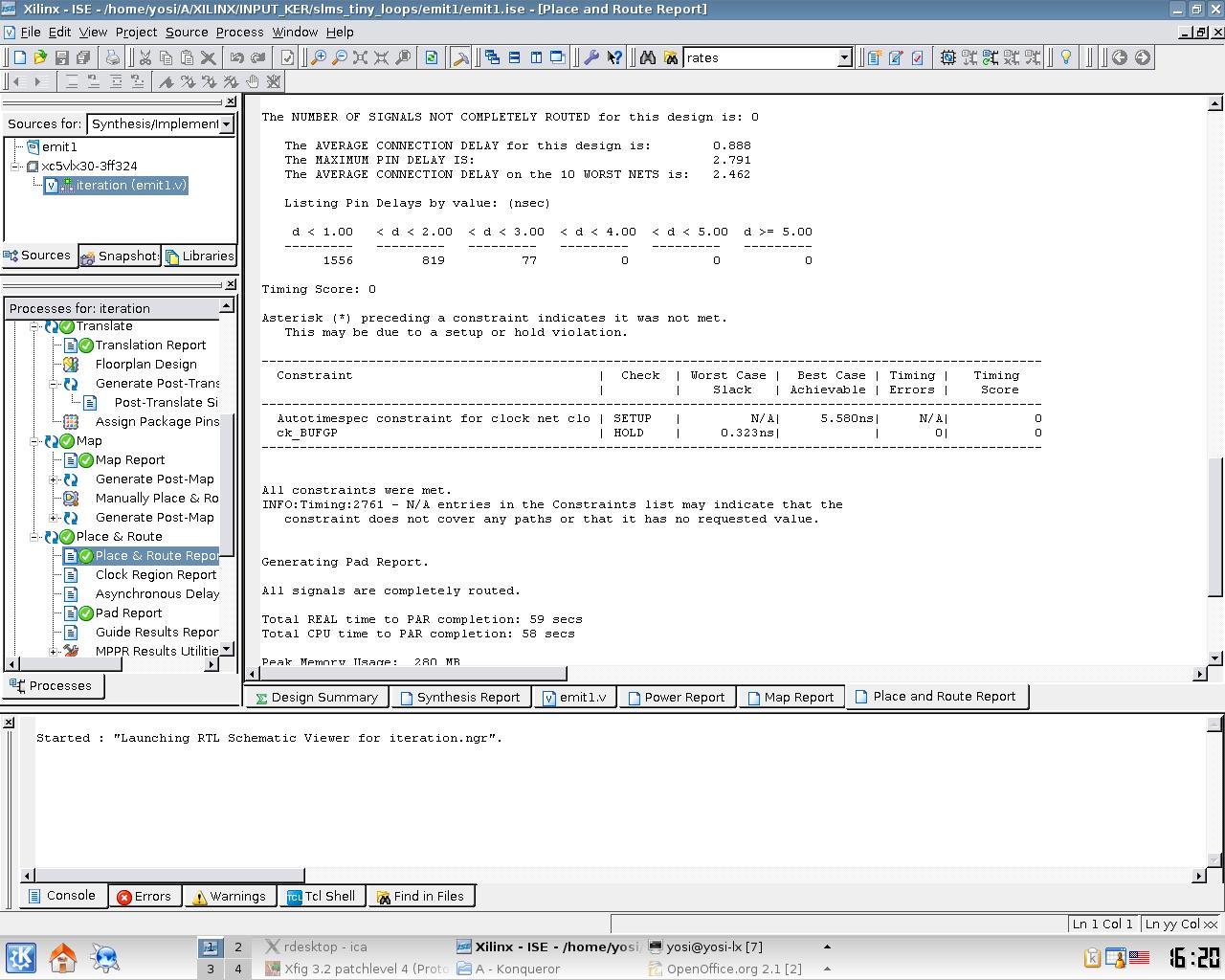
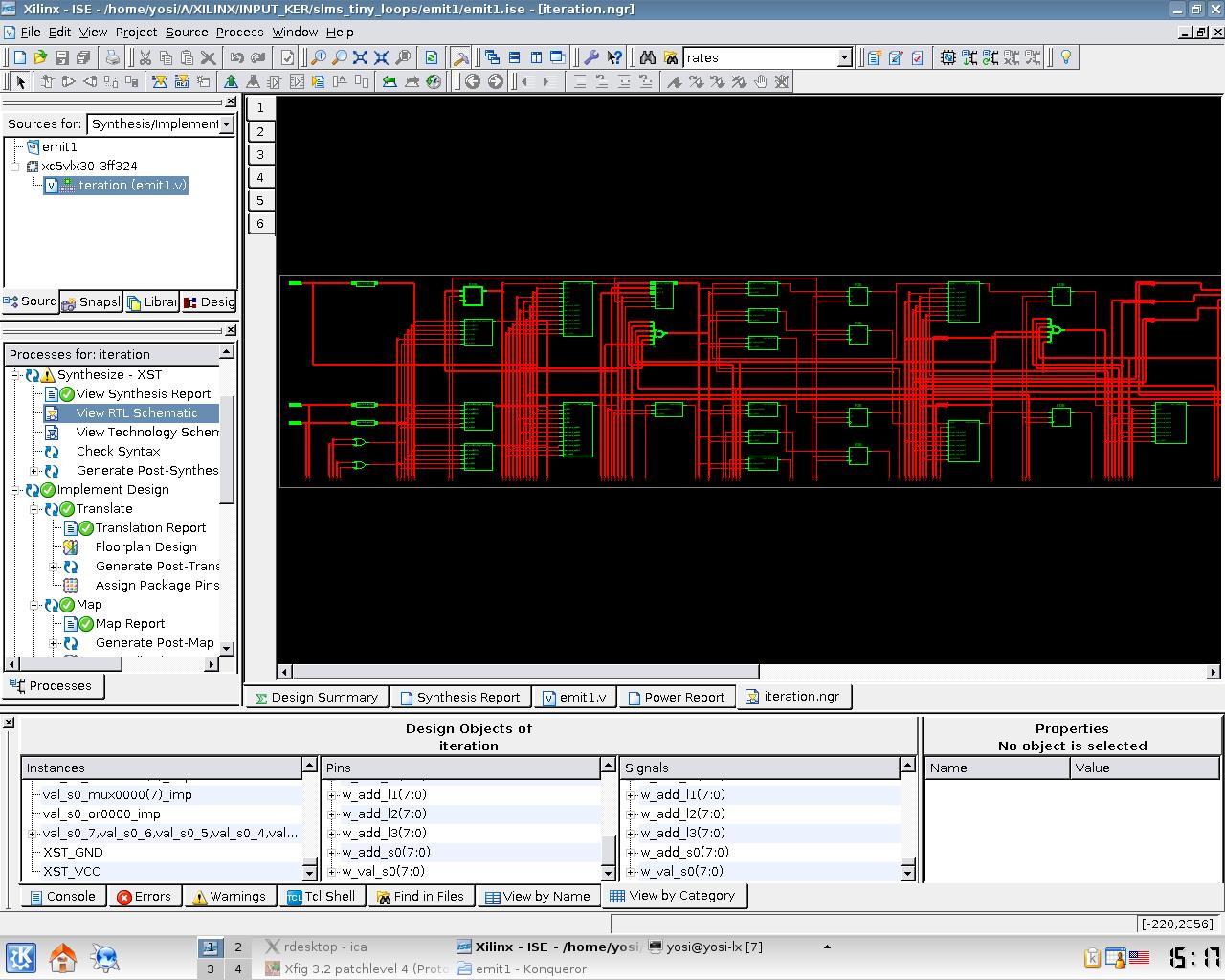
Some screen-shots of the current system with Xilinx's ISE synthesis tool:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Publications: