Multicore shared memory architectures hold a significant premiss to speedup and simplify embedded systems replacing the hardware side by parallel algorithms communicating through shared memory. Two ideas exist as to how shared memory can be constructed from single port memory modules. The first way is to maintain cache-consistency across cores' caches using one repository main memory module. This is how currently shared memory multi-core cpus are built but due the bottleneck of the main memory and the need to invalidate cached copies of variables it is not likely to be scaled to larger numbers of cores. The other way is an older theoretical idea wherein the shared address space is divided between a set of memory modules and a communication network allows each core to access in parallel every such module. This theoretical idea is based on the fact that by a random selection of a hash-function, a pseudo-random mapping of the memory address space to the memory modules can be obtained. In this way the probability that many parallel memory references will collide at the same memory module or at the nodes of the switching network that connects the cores to the memory modules is small.
In the proposed theoretical construction, the shared address space is partitioned to $n$ memory modules. Each core can access any module via a multistage communication network (such as a butterfly network or a hypercube). Every global address can be resolved to a module + internal address in that module. Routing the memory requests to the suitable module and back is done through a communication network. The memory space is hashed so that the probability of $n$ load/store instructions executed by $n$ cores to issue more than $\log n$ memory addresses that have been mapped to the same memory module is polynomialy small. The following figure illustrates the main architecture showing the re-hash unit H and a ring-buffer for external I/O.
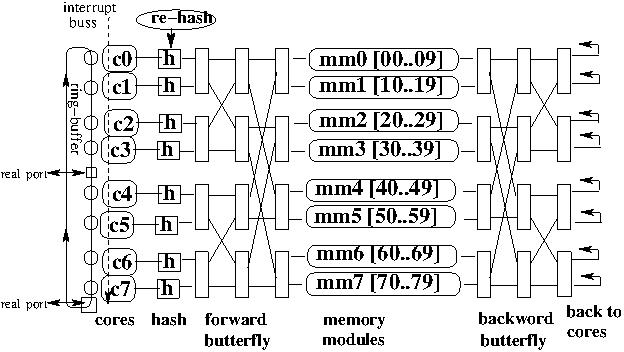{kind=link}
We have designed a simple generic shared memory architecture and synthesized it to $2,4,8,16,\ldots ,1024-cores$ cores for FPGA virtex-7. We used 32-bits PACOBLAZE cores and tested different parameters of this architecture and verified the effectiveness of rehashing to resolve such conflicts. Our results shows that:
- It is better to use a pure combinatorial realization for the butterfly network (connecting the cores o the memory modules) than a multi-stage realization.
We have also studied the ability to use the butterfly network for parallel operations like summing/prefix-sums, and sorting. Currently we have implemented a parallel FFT network that can FFT 2-1024 Complex numbers in 2-25 clock cycles. The FFT switch supports standard 32-bit fix/floating-point arithmetic while the FFT butterfly network is depicted here. The FFT-operation impose synchronization and other computations can be executed while a core waits for its FFT output.
The programming level is currently low, but we plan to use ParC and implement a ParC LLVM compiler that targets this chip. Verilog sources of the core may be obtained for research purposes via Email to yosi@cs.haifa.ac.il.