An application-specific instruction-set processor (ASIP) is (quoting from Wikipedia) a component used in system-on-a-chip design. The instruction set of an ASIP is tailored to benefit a specific application. This specialization of the core provides a tradeoff between the flexibility of a general purpose CPUs and the performance obtained from direct synthesis of a given code segment to a hardware circuit (known as High level synthesis \cite{walker95highlevel,dutt04} or hardware acceleration). As such ASIPs can possibly be used to replace hardware accelerators (HAs) in embedded systems by special instructions that speedup the execution of the software code of these HAs. This implies a CPU architecture that can perform two important features of HAs: A) HAs issue multiple load/store operations in parallel that are executed in parallel to different memory modules; B) HAs use multi-op sub-circuits computing a multi-op computation in one clock cycle. These features must be combined in the pipeline structure of the resulting CPU. If successful, such ASIPs can be used to obtain pure-software embedded systems reducing developing times and improving debugability.
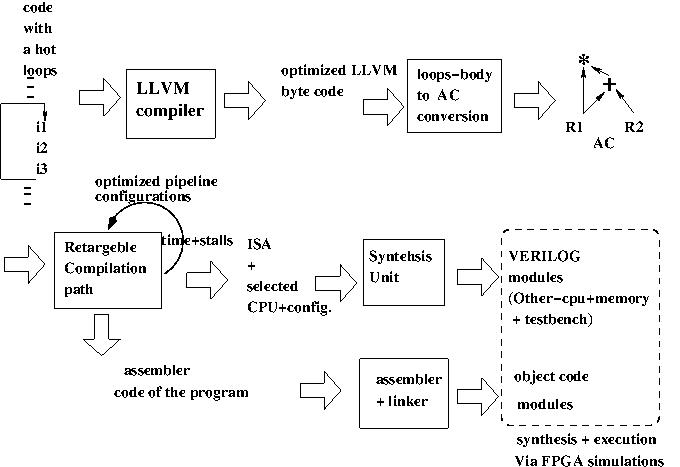
We propose an ASIP compiler system generating adaptable ``thick'' pipeline architectures that targets the execution of complete loop iterations in few/one clock cycle (including parallel memory references and using multi-op circuits). Unlike conventional CPU architectures were pipeline stages correspond to instructions' parts (Fetch, Decode, ALU, MEM Writeback) here pipeline stages correspond to complete instructions of loops' bodies. Thus an OCPU uses multi-op machine instructions which are instructions that can execute several operations including several memory references, e.g., in C-notation, $*(reg1*reg2) = (*reg3)+(*reg4)$ containing two load operations, one store and two arithmetic operations. We also synthesize MUXed/predicated instructions of the form The outcome are non-conventional CPU architectures with optimized thick pipeline units attempting to compress complete loop iterations into a single multi-op instructions. Preliminary results show that both properties of throughput and small area can be achieved.
- They use {\bf multi-op instructions} rather than single-op instructions.
- Their ISA and adaptable structure are mainly focused on the {\bf pipeline-structure} rather than on small variations of the instructions-types which is the case with other ASIPs proposed so far.
The system is based on the LLVM compilers use high unrolling factors to generate large graphs $G$s out of loops bodies. The retargeble compilation pass generates both theoptimized hardware configuration and the optimized ISA that best covers the $G$s. The main engine we are currently using is a greedy bottom-up process that traverses the leaf-nodes $v_1,v_2,...$ and for each pipe-configuration finds the maximal sub-graph in $G$ that match the pipeline's units' order and $v_i$. The best sub-graph is removed from $G$ and suitable instruction is emitted. We use a simple scheduling+register_allocation process. Note that the scheduling determines the order in which the different pipelines are used for the matching so maybe it is not that simple. Another, more complicated algorithm that first generates all possible sub-graphs for every pipeline was also implemented and used. This process of finding and removing a best matching sub-graph is repeated untill $G$ is fully covered.
{kind=link}