Change Eye Gaze Direction
/ Open Closed Eyes
Abstract
It has been, always, a big challenge, when taking a picture, to have an appropriate gaze, and a good eyes’ direction, avoiding eyes’ blink and red eyes. Unfortunately, those important elements are not achieved in most pictures.
In our project, we intend to overcome these technical artifacts, in order to have a better picture.
We took a face picture with “damaged” eyes, detected the eyes region, found suitable eyes to this particular face, from a predefined dataset, and “implanted” each eye in it’s appropriate place (instead of the original eyes).

Goal
Our goal is to “correct unsuccessful” face pictures, and get them to the best situation they could be.
Our vision is to see this new idea, becoming a practical and useful feature in all kinds of cameras, so that regular people can use it to have better pictures for themselves and their beloved ones.

Methods
To implement our project we use several methods as:
- Face and Eye Detection:
For face detection and eye detection we use the matlab vision.CascadeObjectDetector system object which uses the Viola-Jones algorithm to detect people's faces and eyes.
The Viola–Jones object detection framework is the first object detection framework to provide competitive object detection rates in real-time. Although it can be trained to detect a variety of object classes, it was motivated primarily by the problem of face detection.
Components of the framework:
- Feature types and evaluation:
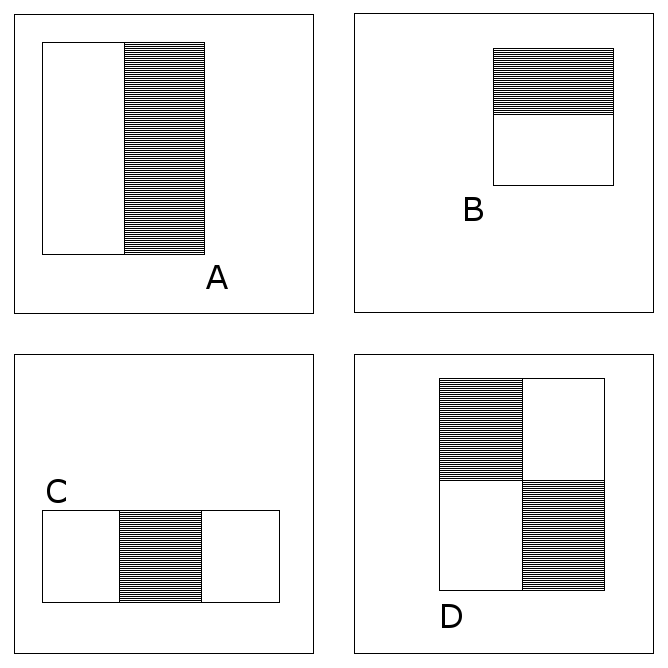
The feature employed by the detection framework universally involve the sums of image pixels within rectangular areas. As such, they bear some resemblance to Haar basis functions, which have been used previously in the realm of image-based object detection. However, since the features used by Viola and Jones all rely on more than one rectangular area, they are generally more complex. Figure1 illustrates the four different types of features used in the framework. The value of any given feature is always simply the sum of the pixels within clear rectangles subtracted from the sum of the pixels within shaded rectangles.
- Learning algorithm:
The speed with which features may be evaluated does not adequately compensate for their number, however. For example, in a standard 24x24 pixel sub-window, there are a total of 162,336 possible features, and it would be prohibitively expensive to evaluate them all. Thus, the object detection framework employs a variant of the learning algorithm AdaBoost to both select the best features and to train classifiers that use them.
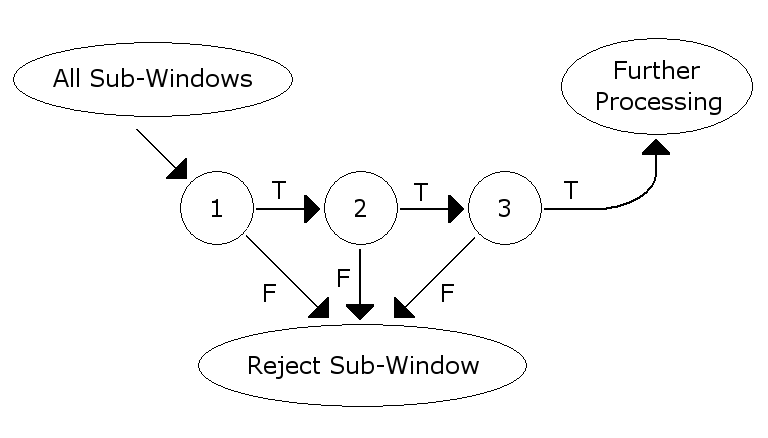
- Cascade architecture:
The evaluation of the strong classifiers generated by the learning process can be done quickly, but it isn’t fast enough to run in real-time. For this reason, the strong classifiers are arranged in a cascade in order of complexity, where each successive classifier is trained only on those selected samples which pass through the preceding classifiers. If at any stage in the cascade a classifier rejects the sub-window under inspection, no further processing is performed and continue on searching the next sub-window (see figure at right). The cascade therefore has the form of a degenerate tree. In the case of faces, the first classifier in the cascade – called the attentional operator – uses only two features to achieve a false negative rate of approximately 0% and a false positive rate of 40%.[5] The effect of this single classifier is to reduce by roughly half the number of times the entire cascade is evaluated.
- Feature types and evaluation:
- Multiband Blending:
-
Our blending consists of the following steps :
- we build laplacian pyramid for each image. (with 10 levels each)
- the blending is done for each level in the laplacian pyramid alone. and the result is saved in a new laplacian pyramid.
- then we collapse the laplacian pyramid - in order to get the blended image.
-
Our blending consists of the following steps :
- Face verification:
In order to find the "suitable eyes", we used a simple version of "Feature Correlation Filter for Face Recognition" to find the most similar face from the reference people face dataset (the lookalike).
Its based on a common approach to overcome the effect of facial expression, pose, aging, illumination changes, etc... by using face representations that are relatively insensitive to those variations. It uses correlation to characterize the similarity between faces, as the natural choice, because of its shift-invariant property and the optimality in the presence of additive white Gaussian noise. (for more information about "Feature Correlation Filter for Face Recognition" see the paper) - Dataset (reference people):
As larger, "smarter" and more diverse the dataset gets, the result will be better... for this sake, we downloaded a dataset called "Utrecht ECVP", 120 images, 42 men, 18 women, different race, age, gender... two photos for each person, collected at the European Conference on Visual Perception in Utrecht, 2008.
To make it better, we also took more photos of people we know, and added them to the dataset. Resulting in total of 152 photos of 76 persons (53 men and 23 women).

In order to test the face verification component, we also took photos of two brothers or two sisters who look alike, added photos of one of them to the reference dataset and demanded to find the most similar face of the other brother/sister. The results was clearly good, more than 60% found the brother/sister, the other 40% found someone quite similar.


Miss match:


Results
Here we present some results of various runs of the program.
Good results - pictures of people who do not have other pictures in the database:




Good results - pictures of people who do have other pictures in the database:




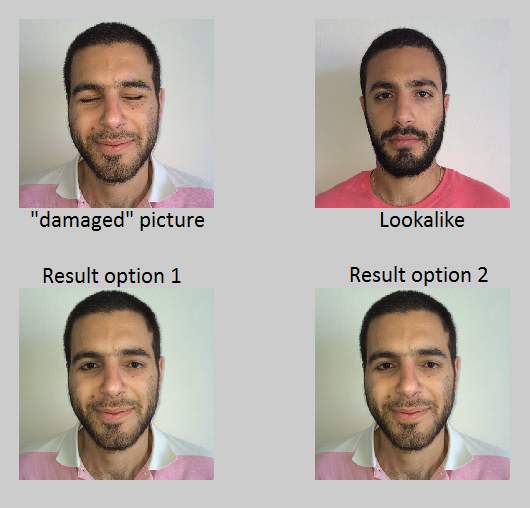
Poor matching (finding a lookalike that is not similar), resulting poor results. though, implanting the eyes works great:




Good matching (finding the most similar lookalike), but, implanting the eyes is not good enough (the eyes region is not in the same shape):
Future Improvements
As you can see, this feature is not illumination invariant, though the detectors and the face verifier are, the final results may have difference in colors as
result of different illumination sources or strength. Therefore, a possible future improvements will be finding a "good" way for blending the eye region while
making sure to change the "lookalike" picture to fit the "damaged" picture colors.
Also, it would be better if we improve the face verifier. At first we thought about implementing one, from a paper named: "Attribute and Simile Classifiers
for Face Verification", this method works great and can be changed to fit our needs more, but this would have been a whole project itself.
About
Final Project in Computational Photography course, Department of Computer Science, Haifa University; Submitted by Areej Khoury, Ameer Abu-Zhaya, and Bahjat Musa - July 2014